Juissie.jl
JUISSIE is a Julia-native semantic query engine, is versatile for integration as a package in software development workflows or through its desktop user interface.
Introduction
Juissie is a Julia-native semantic query engine. It can be used as a package in software development workflows, or via its desktop user interface.
Juissie was developed as a class project for CSCI 6221: Advanced Software Paradigms at The George Washington University.
Installation
- Clone this repo
- Navigate into the cloned repo directory:
cd JuissieIn general, we assume the user is running the julia command, and all other commands (e.g., jupyter notebook), from the root level of this project.
- Open the Julia REPL by typing
juliainto the terminal. Then, install the package dependencies:
using Pkg
Pkg.activate(".")
Pkg.resolve()
Pkg.instantiate()To use our generators, you may need an OpenAI API key see here. To run our demo Jupyter notebooks, you may need to setup Jupyter see here.
Verify setup
- From this repo's home directory, open the Julia REPL by typing
juliainto the terminal. Then, try importing the Juissie module:
using JuissieThis should expose symbols like Corpus, Embedder, upsert_chunk, upsert_document, search, and embed.
- Try instantiating one of the exported struct, like
Corpus:
corpus = Corpus()We can test the upsert and search functionality associated with Corpus like so:
upsert_chunk(corpus, "Hold me closer, tiny dancer.", "doc1")
upsert_chunk(corpus, "Count the headlights on the highway.", "doc1")
upsert_chunk(corpus, "Lay me down in sheets of linen.", "doc2")
upsert_chunk(corpus, "Peter Piper picked a peck of pickled peppers. A peck of pickled peppers, Peter Piper picked.", "doc2")Search those chunks:
idx_list, doc_names, chunks, distances = search(
corpus,
"tiny dancer",
2
)The output should look like this:
([1, 3], ["doc1", "doc2"], ["Hold me closer, tiny dancer.", "Lay me down in sheets of linen."], Vector{Float32}[[5.198073, 9.5337925]])Usage
Desktop UI
Navigate to the root directory of this repository (Juissie.jl), enter the following into the command line, and press the enter/return key:
julia src/Frontend.jlThis will launch our application:
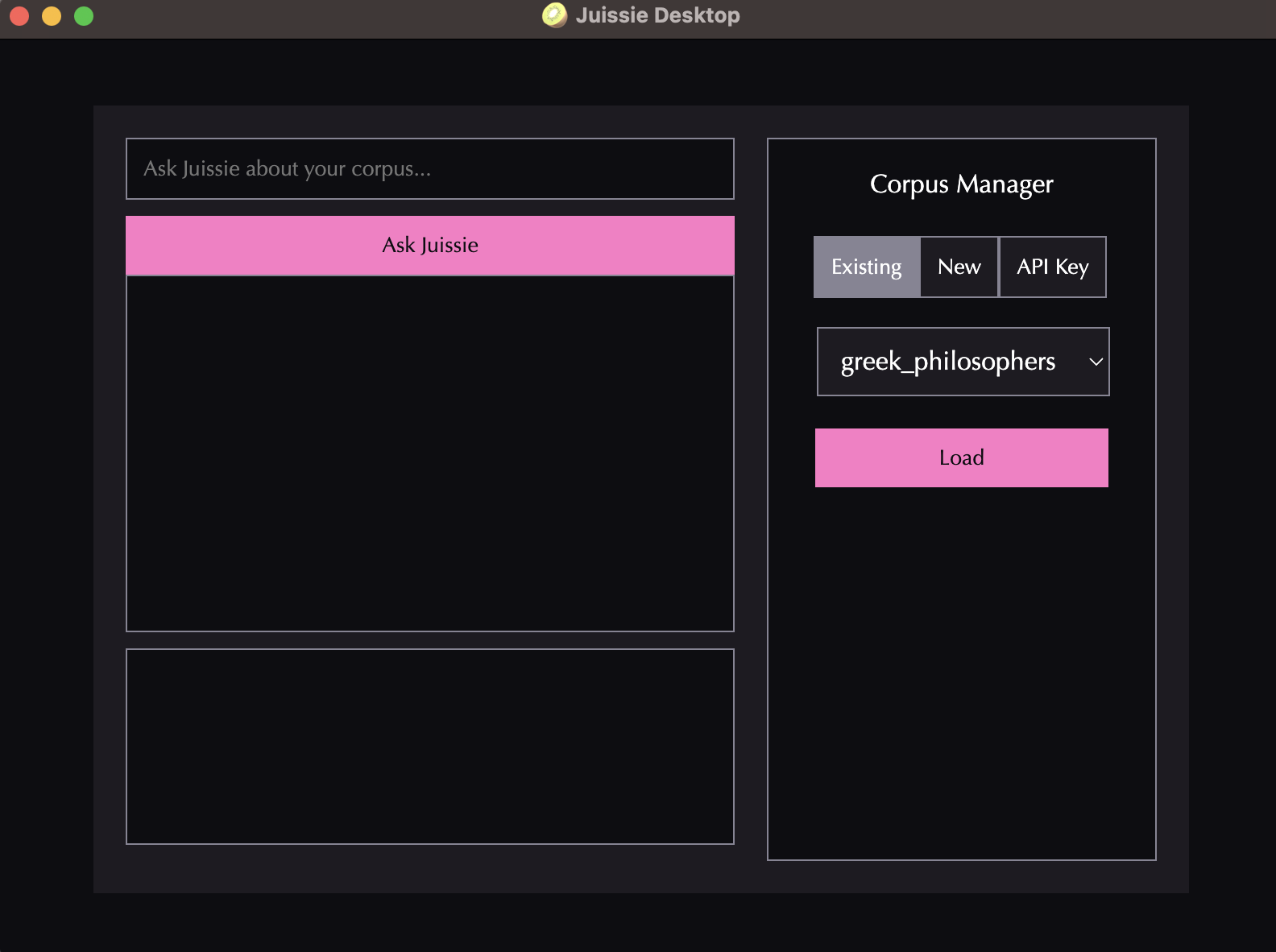
API Keys
Juissie's default generator requires an OpenAI API key. This can be provided manually in the UI (see the API Key tab of the Corpus Manager) or passed as an argument when initializing the generator. The preferred method, however, is to stash your API key in a .env file.
Obtaining an OpenAI API Key
- Create an OpenAI account here.
- Set up billing information (each query has a small cost) here.
- Create a new secret key here.
Managing API Keys
Secure management of secret keys is important. Every user should create a .env file in the project root where they add their API key(s), e.g.:
OAI_KEY=ABC123These may be accessed using Julia via the DotEnv library. First, run the julia command in a terminal. Then install DotEnv:
import Pkg
Pkg.add("DotEnv")Then, use it to access environmental variables from your .env file:
using DotEnv
cfg = DotEnv.config()
api_key = cfg["OAI_KEY"]Note that DotEnv looks for .env in the current directory, i.e. that of where you called julia from. If .env is in a different path, you have to provide it, e.g. DotEnv.config(YOUR_PATH_HERE). If you are invoking Juissie from the root directory of this repo (typical), this means the .env should be placed there.
Functions
Juissie.Generation.SemanticSearch.Embedding.embed — Methodfunction embed(embedder::Embedder, text::String)::AbstractVectorEmbeds a textual sequence using a provided model
Parameters
embedder : Embedder an initialized Embedder struct text : String the text sequence you want to embed
Notes
This is sort of like a class method for the Embedder
Julia has something called multiple dispatch that can be used to make this cleaner, but I'm going to handle that at a later times
Juissie.Generation.SemanticSearch.Embedding.embed_from_bert — Methodfunction embed_from_bert(embedder::Embedder, text::String)Embeds a textual sequence using a provided Bert model
Parameters
embedder : Embedder an initialized Embedder struct the associated model and tokenizer should be Bert-specific text : String the text sequence you want to embed
return : cls_embedding The results from passing the text through the encoder, throught the model, and after stripping
Juissie.Generation.SemanticSearch.Embedding.Embedder — Typestruct EmbedderA struct for holding a model and a tokenizer
Attributes
tokenizer : a tokenizer object, e.g. BertTextEncoder maps your string to tokens the model can understand model : a model object, e.g. HGFBertModel the actual model architecture and weights to perform inference with
Notes
You can get class-like behavior in Julia by defining a struct and functions that operate on that struct.
Juissie.Generation.SemanticSearch.Embedding.Embedder — Methodfunction Embedder(model_name::String)Function to initialize an Embedder struct from a HuggingFace model path.
Parameters
model_name : String a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5"
Juissie.SemanticSearch.Backend.index — Methodfunction index(corpus::Corpus)Constructs the HNSW vector index from the data available. If the corpus has a corpus_name, then we also save the new index to disk. Must be run before searching.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use
Juissie.SemanticSearch.Backend.load_corpus — Methodfunction load_corpus(corpus_name)Loads an already-initialized corpus from its associated "artifacts" (relational database, vector index, and informational json).
Parameters
corpus_name : str the name of your EXISTING vector database
Juissie.SemanticSearch.Backend.search — Functionfunction search(corpus::Corpus, query::String, k::Int=5)Performs approximate nearest neighbor search to find the items in the vector index closest to the query.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use query : str The text you want to search, e.g. your question We embed this and perform semantic retrieval against the vector db k : int The number of nearest-neighbor vectors to fetch
Juissie.SemanticSearch.Backend.upsert_chunk — Methodfunction upsert_chunk(corpus::Corpus, chunk::String, doc_name::String)Given a new chunk of text, get embedding and insert into our vector DB. Not actually a full upsert, because we have to reindex later. Process:
- Generate an embedding for the text
- Insert metadata into database
- Increment idx counter
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use chunk : str This is the text content of the chunk you want to upsert docname : str The name of the document that chunk is from. For instance, if you were upserting all the chunks in an academic paper, docname might be the name of that paper
Notes
If the vectors have been indexed, this de-indexes them (i.e., they need to be indexed again). Currently, we handle this by setting hnsw to nothing so that it gets caught later in search.
Juissie.SemanticSearch.Backend.upsert_document — Methodfunction upsert_document(corpus::Corpus, doc_text::String, doc_name::String)Upsert a whole document (i.e., long string). Does so by splitting the document into appropriately-sized chunks so no chunk exceeds the embedder's tokenization max sequence length, while prioritizing sentence endings.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use doctext : str A long string you want to upsert. We will break this into chunks and upsert each chunk. docname : str The name of the document the content is from
Juissie.SemanticSearch.Backend.upsert_document — Methodfunction upsert_document(corpus::Corpus, documents::Vector{String}, doc_name::String)Upsert a collection of documents (i.e., a vector of long strings). Does so by upserting each entry of the provided documents vector (which in turn will chunkify, each document further into appropriately sized chunks).
See the upsert_document(...) above for more details
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use documents : Vector{String} a collection of long strings to upsert. doc_name : str The name of the document the content is from
Juissie.SemanticSearch.Backend.upsert_document_from_pdf — Methodfunction upsert_document_from_pdf(corpus::Corpus, filePath::String, doc_name::String)Upsert all the data in a PDF file into the provided corpus. See the upsert_document(...) above for more details.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use filePath : String The path to the PDF file to read doc_name : str The name of the document the content is from
Juissie.SemanticSearch.Backend.upsert_document_from_txt — Methodfunction upsert_document_from_txt(corpus::Corpus, filePath::String, doc_name::String)Upsert all the data from the text file into the provided corpus.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use filePath : String The path to the txt file to read doc_name : str The name of the document the content is from
Juissie.SemanticSearch.Backend.upsert_document_from_url — Functionfunction upsert_document_from_url(corpus::Corpus, url::String, doc_name::String, elements::Array{String}=["h1", "h2", "p"])Extracts element-tagged text from HTML and upserts as a document.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use url : String The url you want to scrape for text doc_name : str The name of the document the content is from elements : Array{String} A list of HTML elements you want to pull the text from
Juissie.SemanticSearch.Backend.Corpus — Typestruct CorpusBasically a vector database. It will have these attributes:
- a relational database (SQLite)
- a vector index (HNSW)
- an embedder (via Embedding.jl)
Attributes
corpusname : String or Nothing this is the name of your corpus and will be used to access saved corpuses if Nothing, we can't save/load and everything will be in-memory db : a SQLite.DB connection object this is a real relational database to store metadata (e.g. chunk text, doc name) hnsw : Hierarchical Navigable Small World object this is our searchable vector index embedder : Embedder an initialized Embedder struct maxseqlen : int The maximum number of tokens per chunk. This should be the max sequence length of the tokenizer data : Vector{Any} The embeddings get stored here before we create the vector index nextidx : int stores the index we'll use for the next-upserted chunk
Notes
The struct is mutable because we want to be able to change things like incrementing next_idx.
Juissie.SemanticSearch.Backend.Corpus — Typefunction Corpus(corpus_name::String, embedder_model_path::String="BAAI/bge-small-en-v1.5")Initializes a Corpus struct.
In particular, does the following:
- Initializes an embedder object
- Creates a SQLite databse with the corpus name. It should have:
- row-wise primary key uuid
- doc_name representing the parent document
- chunk text
We can add more metadata later, if desired
Parameters
corpusname : str or nothing the name that you want to give the database optional. if left as nothing, we use an in-memory database embeddermodelpath : str a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5" maxseq_len : int The maximum number of tokens per chunk. This should be the max sequence length of the tokenizer
Juissie.Generation.SemanticSearch.Backend.index — Methodfunction index(corpus::Corpus)Constructs the HNSW vector index from the data available. If the corpus has a corpus_name, then we also save the new index to disk. Must be run before searching.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use
Juissie.Generation.SemanticSearch.Backend.load_corpus — Methodfunction load_corpus(corpus_name)Loads an already-initialized corpus from its associated "artifacts" (relational database, vector index, and informational json).
Parameters
corpus_name : str the name of your EXISTING vector database
Juissie.Generation.SemanticSearch.Backend.search — Functionfunction search(corpus::Corpus, query::String, k::Int=5)Performs approximate nearest neighbor search to find the items in the vector index closest to the query.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use query : str The text you want to search, e.g. your question We embed this and perform semantic retrieval against the vector db k : int The number of nearest-neighbor vectors to fetch
Juissie.Generation.SemanticSearch.Backend.upsert_chunk — Methodfunction upsert_chunk(corpus::Corpus, chunk::String, doc_name::String)Given a new chunk of text, get embedding and insert into our vector DB. Not actually a full upsert, because we have to reindex later. Process:
- Generate an embedding for the text
- Insert metadata into database
- Increment idx counter
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use chunk : str This is the text content of the chunk you want to upsert docname : str The name of the document that chunk is from. For instance, if you were upserting all the chunks in an academic paper, docname might be the name of that paper
Notes
If the vectors have been indexed, this de-indexes them (i.e., they need to be indexed again). Currently, we handle this by setting hnsw to nothing so that it gets caught later in search.
Juissie.Generation.SemanticSearch.Backend.upsert_document — Methodfunction upsert_document(corpus::Corpus, doc_text::String, doc_name::String)Upsert a whole document (i.e., long string). Does so by splitting the document into appropriately-sized chunks so no chunk exceeds the embedder's tokenization max sequence length, while prioritizing sentence endings.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use doctext : str A long string you want to upsert. We will break this into chunks and upsert each chunk. docname : str The name of the document the content is from
Juissie.Generation.SemanticSearch.Backend.upsert_document — Methodfunction upsert_document(corpus::Corpus, documents::Vector{String}, doc_name::String)Upsert a collection of documents (i.e., a vector of long strings). Does so by upserting each entry of the provided documents vector (which in turn will chunkify, each document further into appropriately sized chunks).
See the upsert_document(...) above for more details
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use documents : Vector{String} a collection of long strings to upsert. doc_name : str The name of the document the content is from
Juissie.Generation.SemanticSearch.Backend.upsert_document_from_pdf — Methodfunction upsert_document_from_pdf(corpus::Corpus, filePath::String, doc_name::String)Upsert all the data in a PDF file into the provided corpus. See the upsert_document(...) above for more details.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use filePath : String The path to the PDF file to read doc_name : str The name of the document the content is from
Juissie.Generation.SemanticSearch.Backend.upsert_document_from_txt — Methodfunction upsert_document_from_txt(corpus::Corpus, filePath::String, doc_name::String)Upsert all the data from the text file into the provided corpus.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use filePath : String The path to the txt file to read doc_name : str The name of the document the content is from
Juissie.Generation.SemanticSearch.Backend.upsert_document_from_url — Functionfunction upsert_document_from_url(corpus::Corpus, url::String, doc_name::String, elements::Array{String}=["h1", "h2", "p"])Extracts element-tagged text from HTML and upserts as a document.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use url : String The url you want to scrape for text doc_name : str The name of the document the content is from elements : Array{String} A list of HTML elements you want to pull the text from
Juissie.Generation.SemanticSearch.Backend.Corpus — Typestruct CorpusBasically a vector database. It will have these attributes:
- a relational database (SQLite)
- a vector index (HNSW)
- an embedder (via Embedding.jl)
Attributes
corpusname : String or Nothing this is the name of your corpus and will be used to access saved corpuses if Nothing, we can't save/load and everything will be in-memory db : a SQLite.DB connection object this is a real relational database to store metadata (e.g. chunk text, doc name) hnsw : Hierarchical Navigable Small World object this is our searchable vector index embedder : Embedder an initialized Embedder struct maxseqlen : int The maximum number of tokens per chunk. This should be the max sequence length of the tokenizer data : Vector{Any} The embeddings get stored here before we create the vector index nextidx : int stores the index we'll use for the next-upserted chunk
Notes
The struct is mutable because we want to be able to change things like incrementing next_idx.
Juissie.Generation.SemanticSearch.Backend.Corpus — Typefunction Corpus(corpus_name::String, embedder_model_path::String="BAAI/bge-small-en-v1.5")Initializes a Corpus struct.
In particular, does the following:
- Initializes an embedder object
- Creates a SQLite databse with the corpus name. It should have:
- row-wise primary key uuid
- doc_name representing the parent document
- chunk text
We can add more metadata later, if desired
Parameters
corpusname : str or nothing the name that you want to give the database optional. if left as nothing, we use an in-memory database embeddermodelpath : str a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5" maxseq_len : int The maximum number of tokens per chunk. This should be the max sequence length of the tokenizer
Juissie.Generation.SemanticSearch.Backend.TextUtils.chunkify — Functionfunction chunkify(text::String, tokenizer, sequence_length::Int=512)Splits a provided text (e.g. paragraph) into chunks that are each as many sentences as possible while keeping the chunk's token lenght below the sequence_length. This ensures that each chunk can be fully encoded by the embedder.
Parameters
text : String The text you want to split into chunks. tokenizer : a tokenizer object, e.g. BertTextEncoder The tokenizer you will be using sequence_length : Int The maximum number of tokens per chunk. Ideally, should correspond to the max sequence length of the tokenizer
Example Usage
>>> chunkify(
'''Hold me closer, tiny dancer. Count the headlights on the highway. Lay me down in sheets of linen. Peter Piper picked a peck of pickled peppers. A peck of pickled peppers Peter Piper picked.
''',
corpus.embedder.tokenizer,
20
)
4-element Vector{Any}:
"Hold me closer, tiny dancer. Count the headlights on the highway."
"Lay me down in sheets of linen."
"Peter Piper picked a peck of pickled peppers."
"A peck of pickled peppers Peter Piper picked."Juissie.Generation.SemanticSearch.Backend.TextUtils.get_files_path — Methodfunction get_files_path()Simple function to return the path to the files subdirectory.
Example Usage
testbinpath = getfilespath()*"test.bin"
Juissie.Generation.SemanticSearch.Backend.TextUtils.read_html_url — Functionread_html_url(url::String, elements::Array{String})Returns a string of text from the provided HTML elements on a webpage.
Parameters
url : String the url you want to read elements : Array{String} html elements to look for in the web page, e.g. ["h1", "p"].
Notes
Defaults to extracting headers and paragraphs
Juissie.Generation.SemanticSearch.Backend.TextUtils.sentence_splitter — Methodfunction sentence_splitter(text::String)Uses basic regex to divide a provided text (e.g. paragraph) into sentences.
Parameters
text : String The text you want to split into sentences.
Notes
Regex is hard to read. The first part looks for spaces following end-of-sentence punctuation. The second part matches at the end of the string.
Regex in Julia uses an r identifier prefix.
References
https://www.geeksforgeeks.org/regular-expressions-in-julia/
Juissie.SemanticSearch.Backend.TxtReader.appendToFile — MethodAppend the given contents into a file specified at filename. A new file will be created if filename doesn't already exist.
NOTE: No ' ' newline character will be appended. It is the caller's responsibility to decide if the contents should have a ' ' newline character or not.
Parameters
filename: String The name of the file to open. Relative file paths are evaluated from the directory where the julia command was run. Typically the root level of the project contents: String The exact text to append into the file.
Juissie.SemanticSearch.Backend.TxtReader.getAllTextInFile — MethodOpen the provided filename, load all the data into memory, and return. This function will also manage the file socket open(...) close(...) properly. If there was an error in opening or reading the file then the empty string will be returned
Parameters
filename: String The name of the file to open. Relative file paths are evaluated from the directory where the julia command was run. Typically the root level of the project
Returns: String The entire contets of the file, or an empty string if there was an issue
Juissie.SemanticSearch.Backend.TxtReader.splitFileIntoParts — MethodA simple script that allows a user to split a large file into multiple smaller files. This will create splits # of children files, each with a file size ~1/splits of the origional target file.
Parameters
fileToSplit : String The name of the file to read and split into multiple parts. If an absolute file path is given then that will be used. Otherwise, relative file paths are evaluated from the location that the julia command was run from (typically the root level of this project) outputFileNameBase : String The template for the name of the children split-out files. Each split out file with have the format of <outputFileNameBase>_<#> where # starts at 1 and increments by 1 for each subsequent file. There will be splits number of children files splits : Int How many children files should be created?
Juissie.Generation.build_full_query — Functionfunction build_full_query(query::String, context::OptionalContext=nothing)Given a query and a list of contextual chunks, construct a full query incorporating both.
Parameters
query : String the main instruction or query string context : OptionalContext, which is Union{Vector{String}, Nothing} optional list of chunks providing additional context for the query
Notes
We use the Alpaca prompt, found here: https://github.com/tatsu-lab/stanford_alpaca with minor modifications that reflect our response preferences.
Juissie.Generation.check_oai_key_format — Methodfunction check_oai_key_format(key::String)Uses regex to check if a provided string is in the expected format of an OpenAI API Key
Parameters
key : String the key you want to check
Notes
See here for more on the regex:
- https://en.wikibooks.org/wiki/IntroducingJulia/Stringsandcharacters#Findingandreplacingthingsinsidestrings
Uses format rule provided here:
- https://github.com/secretlint/secretlint/issues/676
- https://community.openai.com/t/what-are-the-valid-characters-for-the-apikey/288643
Note that this only checks the key format, not whether the key is valid or has not been revoked.
Juissie.Generation.generate — Functiongenerate(generator::Union{OAIGenerator, Nothing}, query::String, context::OptionalContext=nothing, temperature::Float64=0.7)Generate a response based on a given query and optional context using the specified OAIGenerator. This function constructs a full query, sends it to the OpenAI API, and returns the generated response.
Parameters
generator : Union{OAIGenerator, Nothing} an initialized generator (e..g OAIGenerator) leaving this as a union with nothing to note that we may want to support other generator types in the future (e.g. HFGenerator, etc.) query : String the main query string. This is basically your question context : OptionalContext, which is Union{Vector{String}, Nothing} optional list of contextual chunk strings to provide the generator additional context for the query. Ultimately, these will be coming from our vector DB temperature : Float64 controls the stochasticity of the output generated by the model
Juissie.Generation.generate_with_corpus — Functionfunction generate_with_corpus(generator::Union{OAIGenerator, Nothing}, corpus::Corpus, query::String, k::Int=5, temperature::Float64=0.7)Parameters
generator : Union{OAIGenerator, Nothing} an initialized generator (e..g OAIGenerator) leaving this as a union with nothing to note that we may want to support other generator types in the future (e.g. HFGenerator, etc.) corpus : an initialized Corpus object the corpus / "vector database" you want to use query : String the main instruction or query string. This is basically your question k : int The number of nearest-neighbor vectors to fetch from the corpus to build your context temperature : Float64 controls the stochasticity of the output generated by the model
Juissie.Generation.load_OAIGeneratorWithCorpus — Functionfunction load_OAIGeneratorWithCorpus(corpus_name::String, auth_token::Union{String, Nothing}=nothing)Loads an existing corpus and uses it to initialize an GeneratorWithCorpus
Parameters
corpusname : str the name that you want to give the database authtoken :: Union{String, Nothing} this is your OPENAI API key. You can either pass it explicitly as a string or leave this argument as nothing. In the latter case, we will look in your environmental variables for "OAI_KEY"
Notes
corpusname is ordered first because Julia uses positional arguments and authtoken is optional.
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Juissie.Generation.upsert_chunk_to_generator — Methodfunction upsert_chunk_to_generator(generator::GeneratorWithCorpus, chunk::String, doc_name::String)Equivalent to Backend.upsert_chunk, but takes a GeneratorWithCorpus instead of a Corpus.
Parameters
generator : any struct that subtypes GeneratorWithCorpus the generator (with corpus) you want to use chunk : str This is the text content of the chunk you want to upsert docname : str The name of the document that chunk is from. For instance, if you were upserting all the chunks in an academic paper, docname might be the name of that paper
Notes
One would expect Julia's multiple dispatch to allow us to call this upsertchunk, but not so. The conflict arises in Juissie, where we would have both SemanticSearch and Generation exporting upsertchunk. This means any uses of it in Juissie must be qualified, and without doing so, neither actually gets defined.
Juissie.Generation.upsert_document_from_url_to_generator — Functionfunction upsert_document_from_url_to_generator(generator::GeneratorWithCorpus, url::String, doc_name::String, elements::Array{String}=["h1", "h2", "p"])Equivalent to Backend.upsertdocumentfrom_url, but takes a GeneratorWithCorpus instead of a Corpus.
Parameters
generator : any struct that subtypes GeneratorWithCorpus the generator (with corpus) you want to use url : String The url you want to scrape for text doc_name : str The name of the document the content is from elements : Array{String} A list of HTML elements you want to pull the text from
Notes
See note for upsertchunkto_generator - same idea.
Juissie.Generation.upsert_document_to_generator — Methodfunction upsert_document_to_generator(generator::GeneratorWithCorpus, doc_text::String, doc_name::String)Equivalent to Backend.upsert_document, but takes a GeneratorWithCorpus instead of a Corpus.
Parameters
generator : any struct that subtypes GeneratorWithCorpus the generator (with corpus) you want to use doctext : str A long string you want to upsert. We will break this into chunks and upsert each chunk. docname : str The name of the document the content is from
Notes
See note for upsertchunkto_generator - same idea.
Juissie.Generation.OAIGenerator — Typefunction OAIGenerator(auth_token::Union{String, Nothing})Initializes an OAIGenerator struct.
Parameters
authtoken :: Union{String, Nothing} this is your OPENAI API key. You can either pass it explicitly as a string or leave this argument as nothing. In the latter case, we will look in your environmental variables for "OAIKEY"
Notes
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Juissie.Generation.OAIGenerator — Typestruct OAIGeneratorA struct for handling natural language generation via OpenAI's gpt-3.5-turbo completion endpoint.
Attributes
url : String the URL of the OpenAI API endpoint header : Vector{Pair{String, String}} key-value pairs representing the HTTP headers for the request body : Dict{String, Any} this is the JSON payload to be sent in the body of the request
Notes
All natural language generation should be done via a "Generator" object of some kind for consistency. In the future, if we decide to host a model locally or something, we might do that via a HFGenerator struct.
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Juissie.Generation.OAIGeneratorWithCorpus — Typefunction OAIGeneratorWithCorpus(auth_token::Union{String, Nothing}=nothing, corpus::Corpus)Initializes an OAIGeneratorWithCorpus.
Parameters
corpusname : str or nothing the name that you want to give the database optional. if left as nothing, we use an in-memory database authtoken :: Union{String, Nothing} this is your OPENAI API key. You can either pass it explicitly as a string or leave this argument as nothing. In the latter case, we will look in your environmental variables for "OAIKEY" embeddermodelpath : str a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5" maxseq_len : int The maximum number of tokens per chunk. This should be the max sequence length of the tokenizer
Notes
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Juissie.Generation.OAIGeneratorWithCorpus — Typestruct OAIGeneratorWithCorpusLike OAIGenerator, but has a corpus attached.
Attributes
url : String the URL of the OpenAI API endpoint header : Vector{Pair{String, String}} key-value pairs representing the HTTP headers for the request body : Dict{String, Any} this is the JSON payload to be sent in the body of the request corpus : an initialized Corpus object the corpus / "vector database" you want to use
Notes
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Juissie.SemanticSearch.Backend.PdfReader.bufferToString! — MethodExtract the contents of the buffer and convert it into a string objectWARNING: This function will clear out the contents of the buffer
Parameters
buff : The buffer to clear, it's contents will be returned as a string
Juissie.SemanticSearch.Backend.PdfReader.getAllTextInPDF — FunctionExtract all the text data from the provided pdf file.Open the pdf at the provided file location, extract all the text data from it (as far as possible), and return that text data as a vector of strings. Each entry in the rsult vector is the appended sum of some number of pages in the PDF. 100 Pages per entry is default. For example, the getAllTextInPDF(...)[0] will be a long string containing 100 pages worth of data. The next entry represents the next 100 pages, etc.
NOTE: This function is a "best effort" function, meaning that it will try to extract as many pages as it can. But if there are pages that are invalid, or otherwise can not be properly parsed then they will simply be ignored and not included in the returned strings.
Parameters
fileLocation : The full path to the PDF file to open. This should be relative from where the julia command has been run (not relative to this source file)
pagesPerEntry : How many pages should be collected into the buffere before turning it into an entry in the result vector.
Juissie.SemanticSearch.Backend.PdfReader.getPagesFromPdf — MethodCollect and return all the text data found in the pdf file found in the provided page range.Using the provided PDF Handel, loop over all the pages in the range and attempt to extract the text data. All the collected data will be returned.
The specific pages to read are defined by [firstPageInclusive, lastPageInclusive] which (naturally) defines an inclusive range. Meaning the first and last page number will be included in the returned string. These ranges SHOULD be valid (ie, in the range [1, MaxPageCount]) but error checking will coerce the values to a proper range.
Parameters
pdfHandel : The PDF file to extract data from firstPageInclusive : The first page in the range to read lastPageInclusive : The last page in the range to read
Juissie.SemanticSearch.Backend.PdfReader.getPagesFromPdf — MethodCollect and return all the text data found in the pdf file found in the provided page range.Using the provided file path, open the PDF and loop over all the pages in the range and attempt to extract the text data. All the collected data will be returned.
The specific pages to read are defined by [firstPageInclusive, lastPageInclusive] which (naturally) defines an inclusive range. Meaning the first and last page number will be included in the returned string. These ranges SHOULD be valid (ie, in the range [1, MaxPageCount]) but error checking will coerce the values to a proper range.
Parameters
fileLocation : The location of the PDF to read firstPageInclusive : The first page in the range to read lastPageInclusive : The last page in the range to read
Juissie.SemanticSearch.Backend.PdfReader.getPagesInPDF_All — MethodExtract all the text data from the provided pdf file.Open the pdf at the provided file location, extract all the text data from it (as far as possible), and return that text data as a vector of strings. Each entry in the result vector is the data from a single page of the PDF file.
NOTE: This function is a "best effort" function, meaning that it will try to extract as many pages as it can. But if there are pages that are invalid, or otherwise can not be properly parsed then they will simply be ignored and not included in the returned strings.
Parameters
fileLocation : The full path to the PDF file to open. This should be relative from where the julia command has been run (not relative to this source file)
Juissie.Generation.SemanticSearch.Backend.TxtReader.appendToFile — MethodAppend the given contents into a file specified at filename. A new file will be created if filename doesn't already exist.
NOTE: No ' ' newline character will be appended. It is the caller's responsibility to decide if the contents should have a ' ' newline character or not.
Parameters
filename: String The name of the file to open. Relative file paths are evaluated from the directory where the julia command was run. Typically the root level of the project contents: String The exact text to append into the file.
Juissie.Generation.SemanticSearch.Backend.TxtReader.getAllTextInFile — MethodOpen the provided filename, load all the data into memory, and return. This function will also manage the file socket open(...) close(...) properly. If there was an error in opening or reading the file then the empty string will be returned
Parameters
filename: String The name of the file to open. Relative file paths are evaluated from the directory where the julia command was run. Typically the root level of the project
Returns: String The entire contets of the file, or an empty string if there was an issue
Juissie.Generation.SemanticSearch.Backend.TxtReader.splitFileIntoParts — MethodA simple script that allows a user to split a large file into multiple smaller files. This will create splits # of children files, each with a file size ~1/splits of the origional target file.
Parameters
fileToSplit : String The name of the file to read and split into multiple parts. If an absolute file path is given then that will be used. Otherwise, relative file paths are evaluated from the location that the julia command was run from (typically the root level of this project) outputFileNameBase : String The template for the name of the children split-out files. Each split out file with have the format of <outputFileNameBase>_<#> where # starts at 1 and increments by 1 for each subsequent file. There will be splits number of children files splits : Int How many children files should be created?
Juissie.SemanticSearch.Embedding.embed — Methodfunction embed(embedder::Embedder, text::String)::AbstractVectorEmbeds a textual sequence using a provided model
Parameters
embedder : Embedder an initialized Embedder struct text : String the text sequence you want to embed
Notes
This is sort of like a class method for the Embedder
Julia has something called multiple dispatch that can be used to make this cleaner, but I'm going to handle that at a later times
Juissie.SemanticSearch.Embedding.embed_from_bert — Methodfunction embed_from_bert(embedder::Embedder, text::String)Embeds a textual sequence using a provided Bert model
Parameters
embedder : Embedder an initialized Embedder struct the associated model and tokenizer should be Bert-specific text : String the text sequence you want to embed
return : cls_embedding The results from passing the text through the encoder, throught the model, and after stripping
Juissie.SemanticSearch.Embedding.Embedder — Typestruct EmbedderA struct for holding a model and a tokenizer
Attributes
tokenizer : a tokenizer object, e.g. BertTextEncoder maps your string to tokens the model can understand model : a model object, e.g. HGFBertModel the actual model architecture and weights to perform inference with
Notes
You can get class-like behavior in Julia by defining a struct and functions that operate on that struct.
Juissie.SemanticSearch.Embedding.Embedder — Methodfunction Embedder(model_name::String)Function to initialize an Embedder struct from a HuggingFace model path.
Parameters
model_name : String a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5"
Juissie.SemanticSearch.TextUtils.chunkify — Functionfunction chunkify(text::String, tokenizer, sequence_length::Int=512)Splits a provided text (e.g. paragraph) into chunks that are each as many sentences as possible while keeping the chunk's token lenght below the sequence_length. This ensures that each chunk can be fully encoded by the embedder.
Parameters
text : String The text you want to split into chunks. tokenizer : a tokenizer object, e.g. BertTextEncoder The tokenizer you will be using sequence_length : Int The maximum number of tokens per chunk. Ideally, should correspond to the max sequence length of the tokenizer
Example Usage
>>> chunkify(
'''Hold me closer, tiny dancer. Count the headlights on the highway. Lay me down in sheets of linen. Peter Piper picked a peck of pickled peppers. A peck of pickled peppers Peter Piper picked.
''',
corpus.embedder.tokenizer,
20
)
4-element Vector{Any}:
"Hold me closer, tiny dancer. Count the headlights on the highway."
"Lay me down in sheets of linen."
"Peter Piper picked a peck of pickled peppers."
"A peck of pickled peppers Peter Piper picked."Juissie.SemanticSearch.TextUtils.get_files_path — Methodfunction get_files_path()Simple function to return the path to the files subdirectory.
Example Usage
testbinpath = getfilespath()*"test.bin"
Juissie.SemanticSearch.TextUtils.read_html_url — Functionread_html_url(url::String, elements::Array{String})Returns a string of text from the provided HTML elements on a webpage.
Parameters
url : String the url you want to read elements : Array{String} html elements to look for in the web page, e.g. ["h1", "p"].
Notes
Defaults to extracting headers and paragraphs
Juissie.SemanticSearch.TextUtils.sentence_splitter — Methodfunction sentence_splitter(text::String)Uses basic regex to divide a provided text (e.g. paragraph) into sentences.
Parameters
text : String The text you want to split into sentences.
Notes
Regex is hard to read. The first part looks for spaces following end-of-sentence punctuation. The second part matches at the end of the string.
Regex in Julia uses an r identifier prefix.
References
https://www.geeksforgeeks.org/regular-expressions-in-julia/
Juissie.Generation.SemanticSearch.Backend.PdfReader.bufferToString! — MethodExtract the contents of the buffer and convert it into a string objectWARNING: This function will clear out the contents of the buffer
Parameters
buff : The buffer to clear, it's contents will be returned as a string
Juissie.Generation.SemanticSearch.Backend.PdfReader.getAllTextInPDF — FunctionExtract all the text data from the provided pdf file.Open the pdf at the provided file location, extract all the text data from it (as far as possible), and return that text data as a vector of strings. Each entry in the rsult vector is the appended sum of some number of pages in the PDF. 100 Pages per entry is default. For example, the getAllTextInPDF(...)[0] will be a long string containing 100 pages worth of data. The next entry represents the next 100 pages, etc.
NOTE: This function is a "best effort" function, meaning that it will try to extract as many pages as it can. But if there are pages that are invalid, or otherwise can not be properly parsed then they will simply be ignored and not included in the returned strings.
Parameters
fileLocation : The full path to the PDF file to open. This should be relative from where the julia command has been run (not relative to this source file)
pagesPerEntry : How many pages should be collected into the buffere before turning it into an entry in the result vector.
Juissie.Generation.SemanticSearch.Backend.PdfReader.getPagesFromPdf — MethodCollect and return all the text data found in the pdf file found in the provided page range.Using the provided PDF Handel, loop over all the pages in the range and attempt to extract the text data. All the collected data will be returned.
The specific pages to read are defined by [firstPageInclusive, lastPageInclusive] which (naturally) defines an inclusive range. Meaning the first and last page number will be included in the returned string. These ranges SHOULD be valid (ie, in the range [1, MaxPageCount]) but error checking will coerce the values to a proper range.
Parameters
pdfHandel : The PDF file to extract data from firstPageInclusive : The first page in the range to read lastPageInclusive : The last page in the range to read
Juissie.Generation.SemanticSearch.Backend.PdfReader.getPagesFromPdf — MethodCollect and return all the text data found in the pdf file found in the provided page range.Using the provided file path, open the PDF and loop over all the pages in the range and attempt to extract the text data. All the collected data will be returned.
The specific pages to read are defined by [firstPageInclusive, lastPageInclusive] which (naturally) defines an inclusive range. Meaning the first and last page number will be included in the returned string. These ranges SHOULD be valid (ie, in the range [1, MaxPageCount]) but error checking will coerce the values to a proper range.
Parameters
fileLocation : The location of the PDF to read firstPageInclusive : The first page in the range to read lastPageInclusive : The last page in the range to read
Juissie.Generation.SemanticSearch.Backend.PdfReader.getPagesInPDF_All — MethodExtract all the text data from the provided pdf file.Open the pdf at the provided file location, extract all the text data from it (as far as possible), and return that text data as a vector of strings. Each entry in the result vector is the data from a single page of the PDF file.
NOTE: This function is a "best effort" function, meaning that it will try to extract as many pages as it can. But if there are pages that are invalid, or otherwise can not be properly parsed then they will simply be ignored and not included in the returned strings.
Parameters
fileLocation : The full path to the PDF file to open. This should be relative from where the julia command has been run (not relative to this source file)
Juissie.SemanticSearch.Backend.Embedding.embed — Methodfunction embed(embedder::Embedder, text::String)::AbstractVectorEmbeds a textual sequence using a provided model
Parameters
embedder : Embedder an initialized Embedder struct text : String the text sequence you want to embed
Notes
This is sort of like a class method for the Embedder
Julia has something called multiple dispatch that can be used to make this cleaner, but I'm going to handle that at a later times
Juissie.SemanticSearch.Backend.Embedding.embed_from_bert — Methodfunction embed_from_bert(embedder::Embedder, text::String)Embeds a textual sequence using a provided Bert model
Parameters
embedder : Embedder an initialized Embedder struct the associated model and tokenizer should be Bert-specific text : String the text sequence you want to embed
return : cls_embedding The results from passing the text through the encoder, throught the model, and after stripping
Juissie.SemanticSearch.Backend.Embedding.Embedder — Typestruct EmbedderA struct for holding a model and a tokenizer
Attributes
tokenizer : a tokenizer object, e.g. BertTextEncoder maps your string to tokens the model can understand model : a model object, e.g. HGFBertModel the actual model architecture and weights to perform inference with
Notes
You can get class-like behavior in Julia by defining a struct and functions that operate on that struct.
Juissie.SemanticSearch.Backend.Embedding.Embedder — Methodfunction Embedder(model_name::String)Function to initialize an Embedder struct from a HuggingFace model path.
Parameters
model_name : String a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5"
Juissie.SemanticSearch.Backend.TextUtils.chunkify — Functionfunction chunkify(text::String, tokenizer, sequence_length::Int=512)Splits a provided text (e.g. paragraph) into chunks that are each as many sentences as possible while keeping the chunk's token lenght below the sequence_length. This ensures that each chunk can be fully encoded by the embedder.
Parameters
text : String The text you want to split into chunks. tokenizer : a tokenizer object, e.g. BertTextEncoder The tokenizer you will be using sequence_length : Int The maximum number of tokens per chunk. Ideally, should correspond to the max sequence length of the tokenizer
Example Usage
>>> chunkify(
'''Hold me closer, tiny dancer. Count the headlights on the highway. Lay me down in sheets of linen. Peter Piper picked a peck of pickled peppers. A peck of pickled peppers Peter Piper picked.
''',
corpus.embedder.tokenizer,
20
)
4-element Vector{Any}:
"Hold me closer, tiny dancer. Count the headlights on the highway."
"Lay me down in sheets of linen."
"Peter Piper picked a peck of pickled peppers."
"A peck of pickled peppers Peter Piper picked."Juissie.SemanticSearch.Backend.TextUtils.get_files_path — Methodfunction get_files_path()Simple function to return the path to the files subdirectory.
Example Usage
testbinpath = getfilespath()*"test.bin"
Juissie.SemanticSearch.Backend.TextUtils.read_html_url — Functionread_html_url(url::String, elements::Array{String})Returns a string of text from the provided HTML elements on a webpage.
Parameters
url : String the url you want to read elements : Array{String} html elements to look for in the web page, e.g. ["h1", "p"].
Notes
Defaults to extracting headers and paragraphs
Juissie.SemanticSearch.Backend.TextUtils.sentence_splitter — Methodfunction sentence_splitter(text::String)Uses basic regex to divide a provided text (e.g. paragraph) into sentences.
Parameters
text : String The text you want to split into sentences.
Notes
Regex is hard to read. The first part looks for spaces following end-of-sentence punctuation. The second part matches at the end of the string.
Regex in Julia uses an r identifier prefix.
References
https://www.geeksforgeeks.org/regular-expressions-in-julia/
Juissie.Generation.SemanticSearch.Backend.Embedding.embed — Methodfunction embed(embedder::Embedder, text::String)::AbstractVectorEmbeds a textual sequence using a provided model
Parameters
embedder : Embedder an initialized Embedder struct text : String the text sequence you want to embed
Notes
This is sort of like a class method for the Embedder
Julia has something called multiple dispatch that can be used to make this cleaner, but I'm going to handle that at a later times
Juissie.Generation.SemanticSearch.Backend.Embedding.embed_from_bert — Methodfunction embed_from_bert(embedder::Embedder, text::String)Embeds a textual sequence using a provided Bert model
Parameters
embedder : Embedder an initialized Embedder struct the associated model and tokenizer should be Bert-specific text : String the text sequence you want to embed
return : cls_embedding The results from passing the text through the encoder, throught the model, and after stripping
Juissie.Generation.SemanticSearch.Backend.Embedding.Embedder — Typestruct EmbedderA struct for holding a model and a tokenizer
Attributes
tokenizer : a tokenizer object, e.g. BertTextEncoder maps your string to tokens the model can understand model : a model object, e.g. HGFBertModel the actual model architecture and weights to perform inference with
Notes
You can get class-like behavior in Julia by defining a struct and functions that operate on that struct.
Juissie.Generation.SemanticSearch.Backend.Embedding.Embedder — Methodfunction Embedder(model_name::String)Function to initialize an Embedder struct from a HuggingFace model path.
Parameters
model_name : String a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5"
Juissie.Generation.SemanticSearch.TextUtils.chunkify — Functionfunction chunkify(text::String, tokenizer, sequence_length::Int=512)Splits a provided text (e.g. paragraph) into chunks that are each as many sentences as possible while keeping the chunk's token lenght below the sequence_length. This ensures that each chunk can be fully encoded by the embedder.
Parameters
text : String The text you want to split into chunks. tokenizer : a tokenizer object, e.g. BertTextEncoder The tokenizer you will be using sequence_length : Int The maximum number of tokens per chunk. Ideally, should correspond to the max sequence length of the tokenizer
Example Usage
>>> chunkify(
'''Hold me closer, tiny dancer. Count the headlights on the highway. Lay me down in sheets of linen. Peter Piper picked a peck of pickled peppers. A peck of pickled peppers Peter Piper picked.
''',
corpus.embedder.tokenizer,
20
)
4-element Vector{Any}:
"Hold me closer, tiny dancer. Count the headlights on the highway."
"Lay me down in sheets of linen."
"Peter Piper picked a peck of pickled peppers."
"A peck of pickled peppers Peter Piper picked."Juissie.Generation.SemanticSearch.TextUtils.get_files_path — Methodfunction get_files_path()Simple function to return the path to the files subdirectory.
Example Usage
testbinpath = getfilespath()*"test.bin"
Juissie.Generation.SemanticSearch.TextUtils.read_html_url — Functionread_html_url(url::String, elements::Array{String})Returns a string of text from the provided HTML elements on a webpage.
Parameters
url : String the url you want to read elements : Array{String} html elements to look for in the web page, e.g. ["h1", "p"].
Notes
Defaults to extracting headers and paragraphs
Juissie.Generation.SemanticSearch.TextUtils.sentence_splitter — Methodfunction sentence_splitter(text::String)Uses basic regex to divide a provided text (e.g. paragraph) into sentences.
Parameters
text : String The text you want to split into sentences.
Notes
Regex is hard to read. The first part looks for spaces following end-of-sentence punctuation. The second part matches at the end of the string.
Regex in Julia uses an r identifier prefix.
References
https://www.geeksforgeeks.org/regular-expressions-in-julia/
Generation.SemanticSearch.Backend.index — Methodfunction index(corpus::Corpus)Constructs the HNSW vector index from the data available. If the corpus has a corpus_name, then we also save the new index to disk. Must be run before searching.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use
Generation.SemanticSearch.Backend.load_corpus — Methodfunction load_corpus(corpus_name)Loads an already-initialized corpus from its associated "artifacts" (relational database, vector index, and informational json).
Parameters
corpus_name : str the name of your EXISTING vector database
Generation.SemanticSearch.Backend.search — Functionfunction search(corpus::Corpus, query::String, k::Int=5)Performs approximate nearest neighbor search to find the items in the vector index closest to the query.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use query : str The text you want to search, e.g. your question We embed this and perform semantic retrieval against the vector db k : int The number of nearest-neighbor vectors to fetch
Generation.SemanticSearch.Backend.upsert_chunk — Methodfunction upsert_chunk(corpus::Corpus, chunk::String, doc_name::String)Given a new chunk of text, get embedding and insert into our vector DB. Not actually a full upsert, because we have to reindex later. Process:
- Generate an embedding for the text
- Insert metadata into database
- Increment idx counter
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use chunk : str This is the text content of the chunk you want to upsert docname : str The name of the document that chunk is from. For instance, if you were upserting all the chunks in an academic paper, docname might be the name of that paper
Notes
If the vectors have been indexed, this de-indexes them (i.e., they need to be indexed again). Currently, we handle this by setting hnsw to nothing so that it gets caught later in search.
Generation.SemanticSearch.Backend.upsert_document — Methodfunction upsert_document(corpus::Corpus, doc_text::String, doc_name::String)Upsert a whole document (i.e., long string). Does so by splitting the document into appropriately-sized chunks so no chunk exceeds the embedder's tokenization max sequence length, while prioritizing sentence endings.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use doctext : str A long string you want to upsert. We will break this into chunks and upsert each chunk. docname : str The name of the document the content is from
Generation.SemanticSearch.Backend.upsert_document — Methodfunction upsert_document(corpus::Corpus, documents::Vector{String}, doc_name::String)Upsert a collection of documents (i.e., a vector of long strings). Does so by upserting each entry of the provided documents vector (which in turn will chunkify, each document further into appropriately sized chunks).
See the upsert_document(...) above for more details
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use documents : Vector{String} a collection of long strings to upsert. doc_name : str The name of the document the content is from
Generation.SemanticSearch.Backend.upsert_document_from_pdf — Methodfunction upsert_document_from_pdf(corpus::Corpus, filePath::String, doc_name::String)Upsert all the data in a PDF file into the provided corpus. See the upsert_document(...) above for more details.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use filePath : String The path to the PDF file to read doc_name : str The name of the document the content is from
Generation.SemanticSearch.Backend.upsert_document_from_txt — Methodfunction upsert_document_from_txt(corpus::Corpus, filePath::String, doc_name::String)Upsert all the data from the text file into the provided corpus.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use filePath : String The path to the txt file to read doc_name : str The name of the document the content is from
Generation.SemanticSearch.Backend.upsert_document_from_url — Functionfunction upsert_document_from_url(corpus::Corpus, url::String, doc_name::String, elements::Array{String}=["h1", "h2", "p"])Extracts element-tagged text from HTML and upserts as a document.
Parameters
corpus : an initialized Corpus object the corpus / "vector database" you want to use url : String The url you want to scrape for text doc_name : str The name of the document the content is from elements : Array{String} A list of HTML elements you want to pull the text from
Generation.SemanticSearch.Backend.Corpus — Typestruct CorpusBasically a vector database. It will have these attributes:
- a relational database (SQLite)
- a vector index (HNSW)
- an embedder (via Embedding.jl)
Attributes
corpusname : String or Nothing this is the name of your corpus and will be used to access saved corpuses if Nothing, we can't save/load and everything will be in-memory db : a SQLite.DB connection object this is a real relational database to store metadata (e.g. chunk text, doc name) hnsw : Hierarchical Navigable Small World object this is our searchable vector index embedder : Embedder an initialized Embedder struct maxseqlen : int The maximum number of tokens per chunk. This should be the max sequence length of the tokenizer data : Vector{Any} The embeddings get stored here before we create the vector index nextidx : int stores the index we'll use for the next-upserted chunk
Notes
The struct is mutable because we want to be able to change things like incrementing next_idx.
Generation.SemanticSearch.Backend.Corpus — Typefunction Corpus(corpus_name::String, embedder_model_path::String="BAAI/bge-small-en-v1.5")Initializes a Corpus struct.
In particular, does the following:
- Initializes an embedder object
- Creates a SQLite databse with the corpus name. It should have:
- row-wise primary key uuid
- doc_name representing the parent document
- chunk text
We can add more metadata later, if desired
Parameters
corpusname : str or nothing the name that you want to give the database optional. if left as nothing, we use an in-memory database embeddermodelpath : str a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5" maxseq_len : int The maximum number of tokens per chunk. This should be the max sequence length of the tokenizer
Generation.build_full_query — Functionfunction build_full_query(query::String, context::OptionalContext=nothing)Given a query and a list of contextual chunks, construct a full query incorporating both.
Parameters
query : String the main instruction or query string context : OptionalContext, which is Union{Vector{String}, Nothing} optional list of chunks providing additional context for the query
Notes
We base our prompt off the Alpaca prompt, found here: https://github.com/tatsu-lab/stanford_alpaca with minor modifications that reflect our response preferences.
Generation.check_oai_key_format — Methodfunction check_oai_key_format(key::String)Uses regex to check if a provided string is in the expected format of an OpenAI API Key
Parameters
key : String the key you want to check
Notes
See here for more on the regex:
- https://en.wikibooks.org/wiki/IntroducingJulia/Stringsandcharacters#Findingandreplacingthingsinsidestrings
Uses format rule provided here:
- https://github.com/secretlint/secretlint/issues/676
- https://community.openai.com/t/what-are-the-valid-characters-for-the-apikey/288643
Note that this only checks the key format, not whether the key is valid or has not been revoked.
Generation.generate — Functiongenerate(generator::Union{OAIGenerator, Nothing}, query::String, context::OptionalContext=nothing, temperature::Float64=0.7)Generate a response based on a given query and optional context using the specified OAIGenerator. This function constructs a full query, sends it to the OpenAI API, and returns the generated response.
Parameters
generator : Union{OAIGenerator, Nothing} an initialized generator (e..g OAIGenerator) leaving this as a union with nothing to note that we may want to support other generator types in the future (e.g. HFGenerator, etc.) query : String the main query string. This is basically your question context : OptionalContext, which is Union{Vector{String}, Nothing} optional list of contextual chunk strings to provide the generator additional context for the query. Ultimately, these will be coming from our vector DB temperature : Float64 controls the stochasticity of the output generated by the model
Generation.generate_with_corpus — Functionfunction generate_with_corpus(generator::Union{OAIGenerator, Nothing}, corpus::Corpus, query::String, k::Int=5, temperature::Float64=0.7)Parameters
generator : Union{OAIGenerator, Nothing} an initialized generator (e..g OAIGenerator) leaving this as a union with nothing to note that we may want to support other generator types in the future (e.g. HFGenerator, etc.) corpus : an initialized Corpus object the corpus / "vector database" you want to use query : String the main instruction or query string. This is basically your question k : int The number of nearest-neighbor vectors to fetch from the corpus to build your context temperature : Float64 controls the stochasticity of the output generated by the model
Generation.load_OAIGeneratorWithCorpus — Functionfunction load_OAIGeneratorWithCorpus(corpus_name::String, auth_token::Union{String, Nothing}=nothing)Loads an existing corpus and uses it to initialize an OAIGeneratorWithCorpus
Parameters
corpusname : str the name that you want to give the database authtoken :: Union{String, Nothing} this is your OPENAI API key. You can either pass it explicitly as a string or leave this argument as nothing. In the latter case, we will look in your environmental variables for "OAI_KEY"
Notes
corpusname is ordered first because Julia uses positional arguments and authtoken is optional.
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Generation.load_OllamaGeneratorWithCorpus — Functionfunction load_OllamaGeneratorWithCorpus(corpus_name::String, model_name::String = "mistral:7b-instruct")Loads an existing corpus and uses it to initialize an OllamaGeneratorWithCorpus
Parameters
corpusname : str the name that you want to give the database modelname :: String this is an Ollama model tag. see https://ollama.com/library defaults to mistral 7b instruct
Notes
corpusname is ordered first because Julia uses positional arguments and modelname is optional.
Generation.upsert_chunk_to_generator — Methodfunction upsert_chunk_to_generator(generator::GeneratorWithCorpus, chunk::String, doc_name::String)Equivalent to Backend.upsert_chunk, but takes a GeneratorWithCorpus instead of a Corpus.
Parameters
generator : any struct that subtypes GeneratorWithCorpus the generator (with corpus) you want to use chunk : str This is the text content of the chunk you want to upsert docname : str The name of the document that chunk is from. For instance, if you were upserting all the chunks in an academic paper, docname might be the name of that paper
Notes
One would expect Julia's multiple dispatch to allow us to call this upsertchunk, but not so. The conflict arises in Juissie, where we would have both SemanticSearch and Generation exporting upsertchunk. This means any uses of it in Juissie must be qualified, and without doing so, neither actually gets defined.
Generation.upsert_document_from_url_to_generator — Functionfunction upsert_document_from_url_to_generator(generator::GeneratorWithCorpus, url::String, doc_name::String, elements::Array{String}=["h1", "h2", "p"])Equivalent to Backend.upsertdocumentfrom_url, but takes a GeneratorWithCorpus instead of a Corpus.
Parameters
generator : any struct that subtypes GeneratorWithCorpus the generator (with corpus) you want to use url : String The url you want to scrape for text doc_name : str The name of the document the content is from elements : Array{String} A list of HTML elements you want to pull the text from
Notes
See note for upsertchunkto_generator - same idea.
Generation.upsert_document_to_generator — Methodfunction upsert_document_to_generator(generator::GeneratorWithCorpus, doc_text::String, doc_name::String)Equivalent to Backend.upsert_document, but takes a GeneratorWithCorpus instead of a Corpus.
Parameters
generator : any struct that subtypes GeneratorWithCorpus the generator (with corpus) you want to use doctext : str A long string you want to upsert. We will break this into chunks and upsert each chunk. docname : str The name of the document the content is from
Notes
See note for upsertchunkto_generator - same idea.
Generation.OAIGenerator — Typefunction OAIGenerator(auth_token::Union{String, Nothing})Initializes an OAIGenerator struct.
Parameters
authtoken :: Union{String, Nothing} this is your OPENAI API key. You can either pass it explicitly as a string or leave this argument as nothing. In the latter case, we will look in your environmental variables for "OAIKEY"
Notes
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Generation.OAIGenerator — Typestruct OAIGeneratorA struct for handling natural language generation via OpenAI's gpt-3.5-turbo completion endpoint.
Attributes
url : String the URL of the OpenAI API endpoint header : Vector{Pair{String, String}} key-value pairs representing the HTTP headers for the request body : Dict{String, Any} this is the JSON payload to be sent in the body of the request
Notes
All natural language generation should be done via a "Generator" object of some kind for consistency.
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Generation.OAIGeneratorWithCorpus — Typefunction OAIGeneratorWithCorpus(auth_token::Union{String, Nothing}=nothing, corpus::Corpus)Initializes an OAIGeneratorWithCorpus.
Parameters
corpusname : str or nothing the name that you want to give the database optional. if left as nothing, we use an in-memory database authtoken :: Union{String, Nothing} this is your OPENAI API key. You can either pass it explicitly as a string or leave this argument as nothing. In the latter case, we will look in your environmental variables for "OAIKEY" embeddermodelpath : str a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5" maxseq_len : int The maximum number of tokens per chunk. This should be the max sequence length of the tokenizer
Notes
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Generation.OAIGeneratorWithCorpus — Typestruct OAIGeneratorWithCorpusLike OAIGenerator, but has a corpus attached.
Attributes
url : String the URL of the OpenAI API endpoint header : Vector{Pair{String, String}} key-value pairs representing the HTTP headers for the request body : Dict{String, Any} this is the JSON payload to be sent in the body of the request corpus : an initialized Corpus object the corpus / "vector database" you want to use
Notes
When instantiating a new OAIGenerator in an externally-viewable setting (e.g. notebooks committed to GitHub or a public demo), it is important to place a semicolon after the command, e.g. '''generator=loadOAIGeneratorWithCorpus("greekphilosophers");''' to ensure that your OAI API key is not inadvertently shared.
Generation.OllamaGenerator — Typefunction OllamaGenerator(model_name::String = "mistral:7b-instruct")Initializes an OllamaGenerator struct for local text generation.
Parameters
model_name :: String this is an Ollama model tag. see https://ollama.com/library defaults to mistral 7b instruct
Generation.OllamaGenerator — Typestruct OllamaGeneratorA struct for handling natural language generation locally.
Attributes
url : String the URL of the local Ollama API endpoint header : Dict{String,Any} HTTP header for the request body : Dict{String, Any} this is the JSON payload to be sent in the body of the request
Generation.OllamaGeneratorWithCorpus — Typefunction OllamaGeneratorWithCorpus(corpus_name::Union{String,Nothing} = nothing, model_name::String = "mistral:7b-instruct", embedder_model_path::String = "BAAI/bge-small-en-v1.5", max_seq_len::Int = 512)Initializes an OllamaGeneratorWithCorpus.
Parameters
corpusname : str or nothing the name that you want to give the database optional. if left as nothing, we use an in-memory database modelname :: String this is an Ollama model tag. see https://ollama.com/library defaults to mistral 7b instruct embeddermodelpath : str a path to a HuggingFace-hosted model e.g. "BAAI/bge-small-en-v1.5" maxseqlen : int The maximum number of tokens per chunk. This should be the max sequence length of the tokenizer
Generation.OllamaGeneratorWithCorpus — Typestruct_OllamaGeneratorWithCorpusLike OllamaGenerator, but has a corpus attached.
Attributes
url : String the URL of the local Ollama API endpoint header : Dict{String,Any} HTTP header for the request body : Dict{String, Any} this is the JSON payload to be sent in the body of the request corpus : an initialized Corpus object the corpus / "vector database" you want to use
Generation.SemanticSearch.Backend.TextUtils.chunkify — Functionfunction chunkify(text::String, tokenizer, sequence_length::Int=512)Splits a provided text (e.g. paragraph) into chunks that are each as many sentences as possible while keeping the chunk's token lenght below the sequence_length. This ensures that each chunk can be fully encoded by the embedder.
Parameters
text : String The text you want to split into chunks. tokenizer : a tokenizer object, e.g. BertTextEncoder The tokenizer you will be using sequence_length : Int The maximum number of tokens per chunk. Ideally, should correspond to the max sequence length of the tokenizer
Example Usage
>>> chunkify(
'''Hold me closer, tiny dancer. Count the headlights on the highway. Lay me down in sheets of linen. Peter Piper picked a peck of pickled peppers. A peck of pickled peppers Peter Piper picked.
''',
corpus.embedder.tokenizer,
20
)
4-element Vector{Any}:
"Hold me closer, tiny dancer. Count the headlights on the highway."
"Lay me down in sheets of linen."
"Peter Piper picked a peck of pickled peppers."
"A peck of pickled peppers Peter Piper picked."Generation.SemanticSearch.Backend.TextUtils.get_files_path — Methodfunction get_files_path()Simple function to return the path to the files subdirectory.
Example Usage
testbinpath = getfilespath()*"test.bin"
Generation.SemanticSearch.Backend.TextUtils.read_html_url — Functionread_html_url(url::String, elements::Array{String})Returns a string of text from the provided HTML elements on a webpage.
Parameters
url : String the url you want to read elements : Array{String} html elements to look for in the web page, e.g. ["h1", "p"].
Notes
Defaults to extracting headers and paragraphs
Generation.SemanticSearch.Backend.TextUtils.sentence_splitter — Methodfunction sentence_splitter(text::String)Uses basic regex to divide a provided text (e.g. paragraph) into sentences.
Parameters
text : String The text you want to split into sentences.
Notes
Regex is hard to read. The first part looks for spaces following end-of-sentence punctuation. The second part matches at the end of the string.
Regex in Julia uses an r identifier prefix.
References
https://www.geeksforgeeks.org/regular-expressions-in-julia/